Since I started to work with vRealize Operations (vROps) I was amazed by its flexible architecture: by means of a single virtual appliance you can deploy scale-out, high availability and even business continuity deployments. It is extremely flexible as it is suitable for any kind of environment, from small organizations with few systems to big corps with hundreds of thousands of systems under management. It works well for enterprises as well as for service providers.
vROps can be deployed as a single virtual appliance or in multi-nodes clustered deployment. Single node deployment works well for PoCs, trials, assessments and I know some organizations with small environments that are happy with this trivial setup even for prod. However, the majority of organizations that work with vROps (and there are a number of them as vROPs is an extremely popular) run multi-nodes clustered vROps instance to enjoy horizontal scalability, high availability and business continuity.
I’d like to consolidate here some structured and unstructured knowledge about vROps node architecture and internals I stumbled upon over the time across different sources. In this post I’ll try to illustrate what types of nodes are available, their function (this is quite known and well documented) and what runs in each node (this is less documented).
vROps Node Types
vROps is made available to users as a virtual appliance and this provides all the solution’s capabilities so that you can deploy a single appliance (node) and get a fully functional vROps instance. However, in a clustered deployment when you deploy appliances you are requested to assign each node a specific function according to the following list of vROps 8.x nodes types:
- Master (aka Primary Node)
- Master Replica (aka Primary Replica Node)
- Data
- Remote Collector
- Cloud Proxy
- Witness
Master Node
The Master Node is the primary node that is required, it is the initial node in your vROps cluster. The primary node performs administration for the cluster and must be online before you configure and bring online any new nodes. All other nodes are managed by the primary node. If the primary node and replica node go offline together, bring them back online separately. Bring the primary node online first, and then bring the replica node online.
Master Replica Node
The Master Replica Node is the exact copy of the Master Node. This node type is in charge to take over the Master node in case it becomes unavailable/unreachable. This is required to use vRealize Operations high availability (HA) and continuous availability (CA). Basically this node is not doing any real work, but it is just watching the Master Node at all times and synching with the Master to ensure that it can take its place if the Master fails.
Data Node
Data nodes are vROps cluster work horses, they have adapters installed and perform collection and analysis. They are used for scale out purposes. Larger deployments usually have adapters only on data nodes so that primary and replica node resources can be dedicated to cluster management.
Remote Collector Node
A Remote Collector only gather data from a source without storing data or performing analysis. This type of node is used in distributed environments to navigate firewalls, interface with remote data sources, reduce the bandwidth across data centers or reduce the load on the vRealize Operations analytics cluster. In addition, remote collector nodes might be installed on a different operating system than the rest of the cluster.
Cloud Proxy
A Cloud Proxy node extends the Remote Collector capabilities with the ability to deploy, manage and collect data from Telegraf agents. This component was introduced in vROps 8.4 to replace the deprecated Application Remote Collector (ARC) that has been available from vROps 7.5 up to 8.3.
Notes:
- vROPs – Cloud Proxy and vROps Cloud – Cloud Proxy have the same capabilities, however up to the current version 8.6.2 they are not interchangeable. That is you cannot use vROp – Cloud Proxy with vROps Cloud and vice versa.
- Cloud Proxy provides a super set of the Remote Collector capabilities, but at the time of writing I was not able to find plans to deprecate Remote Collector.
Witness Node
To use vRealize Operations continuous availability (CA), the cluster requires a witness node. If the network connection between the two fault domains is lost, the witness node acts as a decision maker regarding the availability of vRealize Operations.
What’s inside nodes
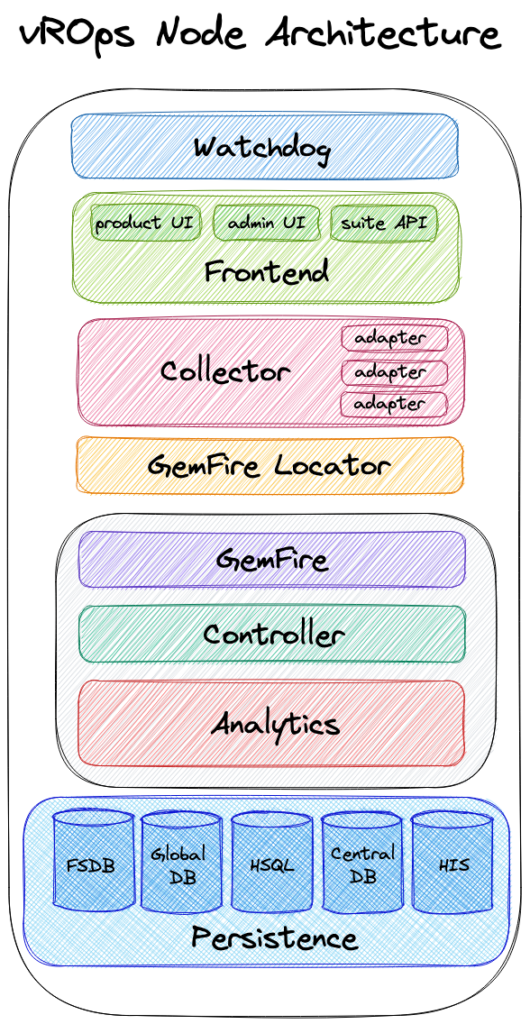
Watchdog
This is a python script that monitors if vROps services are running or not. It checks for services status every 5 minutes and if something is not running the Watchdog tries to restart it. Watchdog checks if PID files exist and the status for services.
Frontend
Fronted is served by means of Apache HTTPD and Tomcat and it is comprised by solution’s User Interfaces and the suite API. vROps UIs are based on VMware Clarity Design system that is an open-source, enterprise-focused design system with a core design principle of inclusion. Actually vROps comes with two User Interfaces: the product UI (accessible from https://<vROps_FQDN_or_IP>) and the admin UI (accessible from https://<vROps_FQDN_or_IP>/admin).
The product UI is the main UI of vROps as it provides access to all the solution capabilities: Dashboards, Reports, Charts, Troubleshooting, Optimizations, What-if Analysis, Costs, Alert, Policy, etc. Among these, the product UI provides access to solution administration tasks such as: licensing, access control, authentication sources, certificates, etc.
The admin UI provides access to selected maintenance functions beyond what the product interface supports such as: enable/disable high availability (HA), business continuity (BC), SSH on nodes; execute cluster management activities (e.g. take node online/offline, add/remove node, reloads nodes, shrink cluster, replace node etc.) and others like apply software updates, manage platform health and workloads.
Finally, the suite API provides access to vROps REST API. The REST API documentation includes reference material for all elements, types, queries, and operations in the vRealize Operations API. It also includes the schema definition files. Swagger based API documentation is available within the product, with the capability of making REST API calls right from the landing page. You can access the API documentation from https://<vROps_FQDN_or_IP>/suite-api
Collector
The Collector is responsible for pulling and processing data from vROps adapter instances. An adapter is a pluggable component that has the ability to collect data from a specific data source. Normal adapters require a one-way communication to the monitored endpoint, while hybrid adapters require a two-way communication. The Collector uses adapters to collect data from various data sources and push the collected data to one or more GemFire cache servers. The Collector leverage the GemFire Locator to know what GemFire cache server(s) in the cluster should receive the data.
GemFire
GemFire is an in memory data grid based on the open source project Apache Geode. This component is responsible to provide access to all the vROps data across all the nodes in the cluster with very low latency.
Controller
The Controller manages the storing and retrieving for all the inventory objects within the system. It is responsible to map the collected data to the right resources and also retrieve data for requested queries. Queries are performed by means of the GemFire MapReduce function that allows to perform efficient data queries as data queries are only performed on specific node(s) rather than all nodes in the cluster.
Analytics
This is a key component of vROps as it responsible for tracking the individual state of every metric and than use various machine learning techniques to determine whether there are problems or not for the related managed object. From a very high level we can summarize Analytics component tasks as follows:
- Metric calculations
- Dynamic thresholds
- Alerts
- Troubleshooting
- Historic Inventory Server (for metadata processing and relationship data)
- Metric storage and retrieval from the Persistence layer
Persistence
This is layer is responsible to manage data with the required performance and scalability needed to manage hundreds of thousands of objects for which data is collected, stored, analyzed and retrieved. It acts as data service layer for all the other components mentioned above and working along with GemFire it provides horizontal scalability, performance and availability. The Persistence layer relies on various type of databases.
FSDB. This is a filesystem database and it stores all the raw time series and supermetrics data collected from adapters and calculated or generated from data analysis. This database leverages sharding to scale horizontally.
Global DB. This database is based on the Apache Cassandra that is an open source NoSQL distributed database. This is used to manage user configurations data such as: user created dashboards and reports, policy settings, supermetrics formulas, user access and roles and others. Cassandra is present on every cluster nodes, but it is only active on the Master and Master Replica nodes.
HSQLDB. HyperSQL database is used for cluster and slice administration. This database is present on every cluster node and it is an in-memory database (it make use of memory of the nodes to store information). This is involved in every cluster administrative action such as taking node offline, taking cluster offline and upgrading vROps. Even though it is present on every node, on this database no sharding occurs.
Central Database. This is also referred as Replication DB, it based on vPostgreSQL DBMS. It stores resources inventory in metadata format and it is used only for supporting high availability configuration. This is present on Master and Master Replica nodes only if high availability is enabled and it leverages sharding. The Central Database on Master and Mater Replica will always be in synch mode.
Historical Inventory Service (HIS). This database is also based on vPostgreSQL DBMS. It stores information about alerts and symptoms history, history of resources properties and history of resources relationships. This database is present on every nodes of the cluster and it leverages sharding.
I hope this helps you. At least it helped me to consolidate some tribal knowledge 🙂