vRealize Automation is made up of multiple components, one of them is Code Stream that allows users to automate application and infrastructure delivery process with release pipeline
management, including visibility and analytics into active pipelines and their status for troubleshooting. To be honest I was not a fan of Code Stream and when a customer engagement requested me to play with it I was not really excited. However, after having played with it I completely changed my mind, Code Stream is VERY easy to pick up, powerful and flexible. In this engagement I had the pleasure to work with my colleague Brice Dereims and hereafter I am sharing with you a glimpse of one of the use cases we setup. In this use case, our customer wanted to move away from a quite opinionated app deployment in OpenShift. Therefore we managed OpenShift as a standard Kubernetes cluster and orchestrated container image build and deployment through Code Stream. In this engagement we leveraged vRealize Automation Cloud a Software as a Service offering.
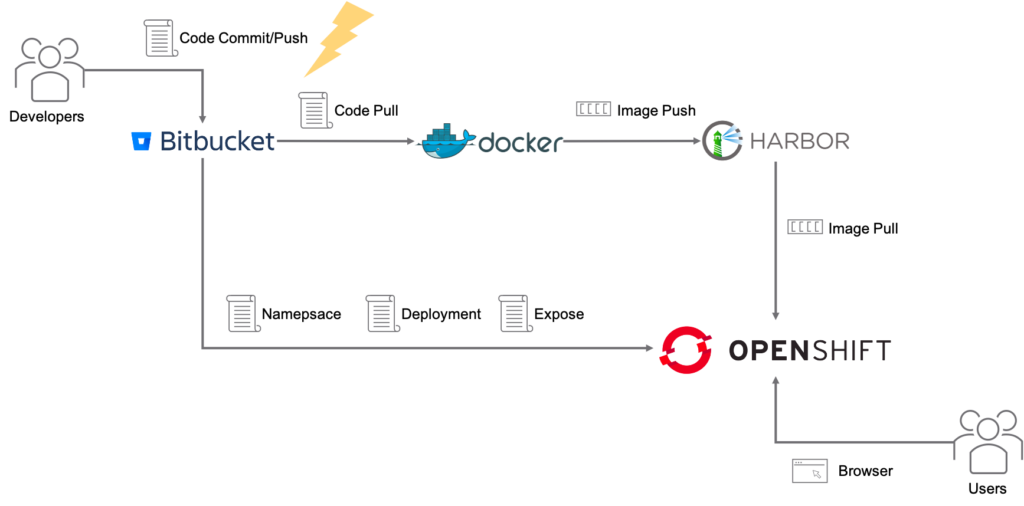
We build a simple proof of concept pipeline (see picture below) made up of following bits as per customer specifics: Bitbucket Enterprise, OpenShift cluster, Harbor and a Docker Host. For each of them a Code Stream Endpoint was created. This pipeline works as follows: when a developer pushes code to the repo the Code Stream pipeline is triggered and it picks the new code from the repo, move it to the Docker Host in order to build a new container image version that is then stored into Harbor registry. A new namespaces is created on OpenShift cluster, the new app version is deployed (pulling the image from Harbor registry) and finally the service is exposed to users (in our case a browser automation test tool).
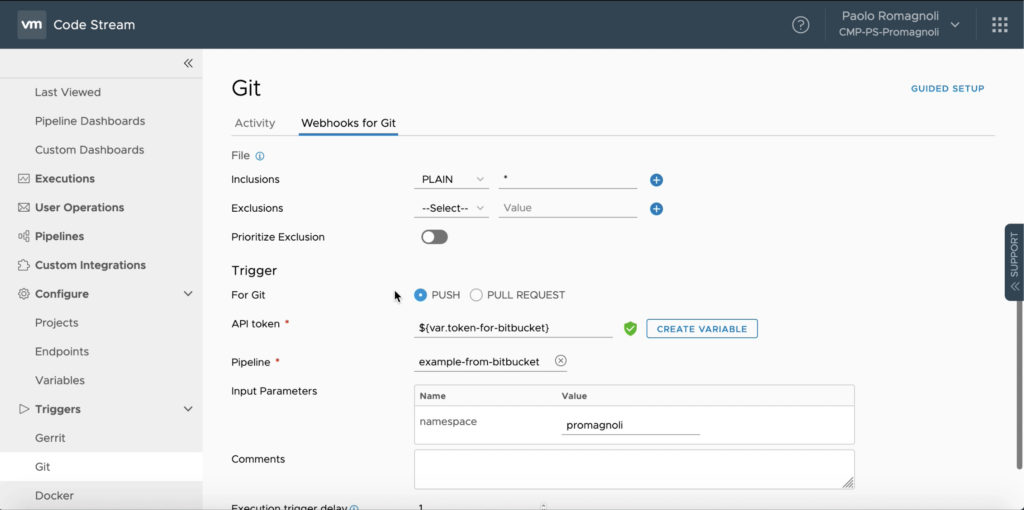
After having configured all the Endpoint in Code stream, we created a Git Trigger: Code Stream enables to automatically create webhook in code repo and this webhook offers the possibility to trigger a given pipeline when a specific event occurs. Code Stream provides user with a good level of control on defining what specific action(s) should trigger pipeline execution. This enables “GitOps” approach, in our use case when a dev executes “git push” against the Bitbucket code repo our pipeline is automatically executed.
Let’s now dig into the pipeline. We defined 3 stages: Build, Deploy and Create App Route. The Build stage is made up of 2 tasks, the firts is named Docker build and it basically clones the repo on the Docker Host, build a new docker image based on the code in the repo and tag it as per customer convention. The picture below allows me to introduce that Code Stream allows to define Environment Variables (task local variables) and Variables that can be used across pipelines of projects and provide a built-in secret vault. There are 3 type of Variables: Regular (Plain text values), Secret (Value is encrypted and saved) and Restricted (Value is encrypted and usage is restricted).
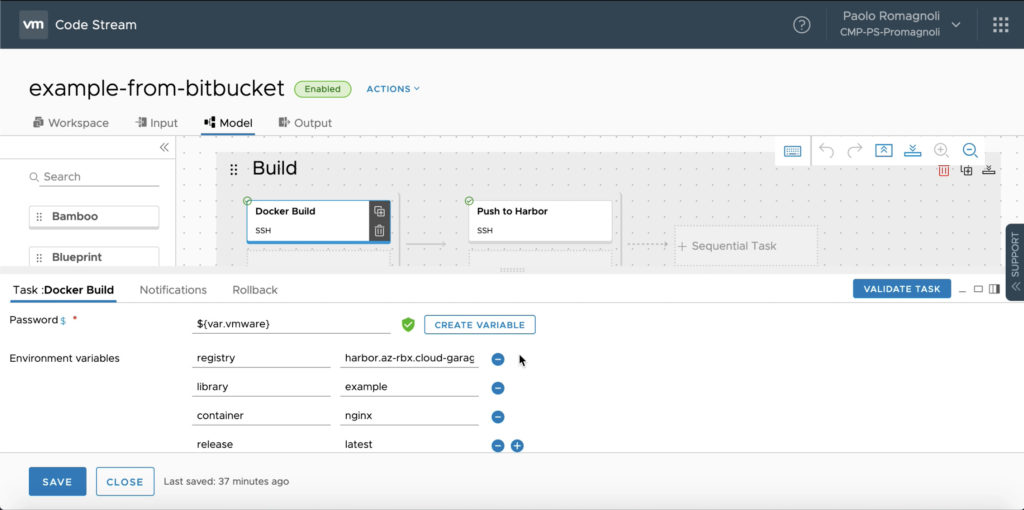
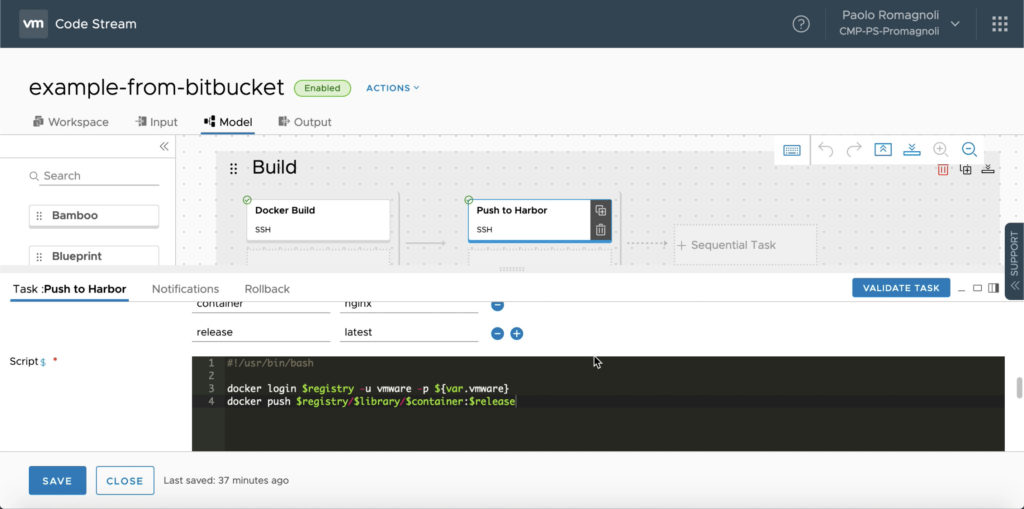
The second task of the Build stage is named Push to Harbor and … it pushes the newly created image to the Harbor registry :). With the picture below I’d like to introduce you that you can type scripts into to Code Stream tasks or get them from an external repo. In any case you can parametrize your script with Environment Variables (syntax is $your-env-variable) and Variables (syntax is ${var.your-variable}). Of course you can assign an Environment Variable the value of a Variable.
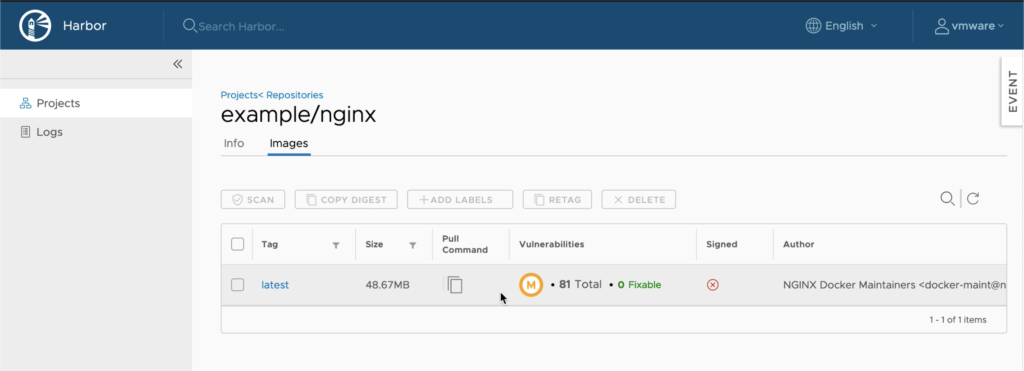
The picture below shows the outcome of the Push to Harbor task.
The second stage (Deploy) is made up of 4 tasks, the first task takes care of the SCC Security Context Constraints to control privileges to be assigned to our app pods. This is something very specific to OpenShift, while the others tasks execute actions against the OpenShift cluster leveraging upstream Kubernetes API and leverages manifests stored in the Bitbucket repo. Of course, the configurations created in these 3 stages could be carried out in a single task, however splitting them into multiple tasks doesn’t impact performance and provides more control and visibility on the pipeline. The configurations applied are: create a new namespace, create a deployment (with our newly created container image) and expose the app to users. The 3 tasks that does these configurations work in the same way, apply a manifest file stored into a specific repo
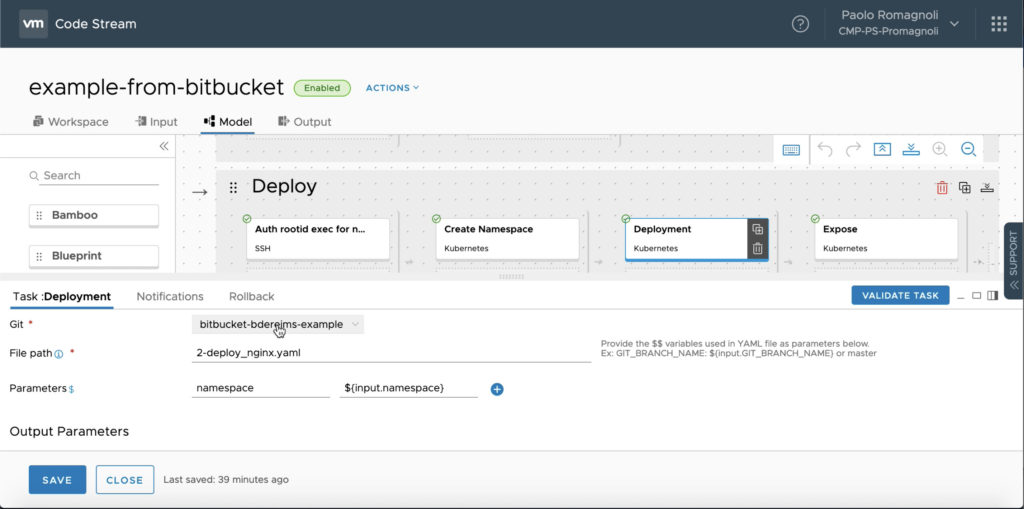
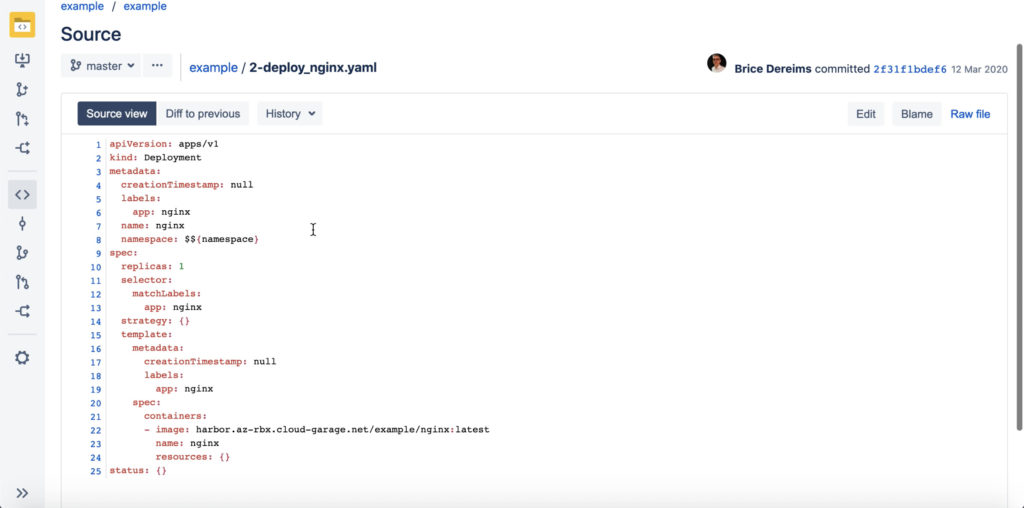
The picture below shows the manifest file used in this deployment, this is a very simple deployment but it is worth to note how Code Stream variables are bind to files. $${namespace} in yaml will be updated by Code Stream during pipeline execution.
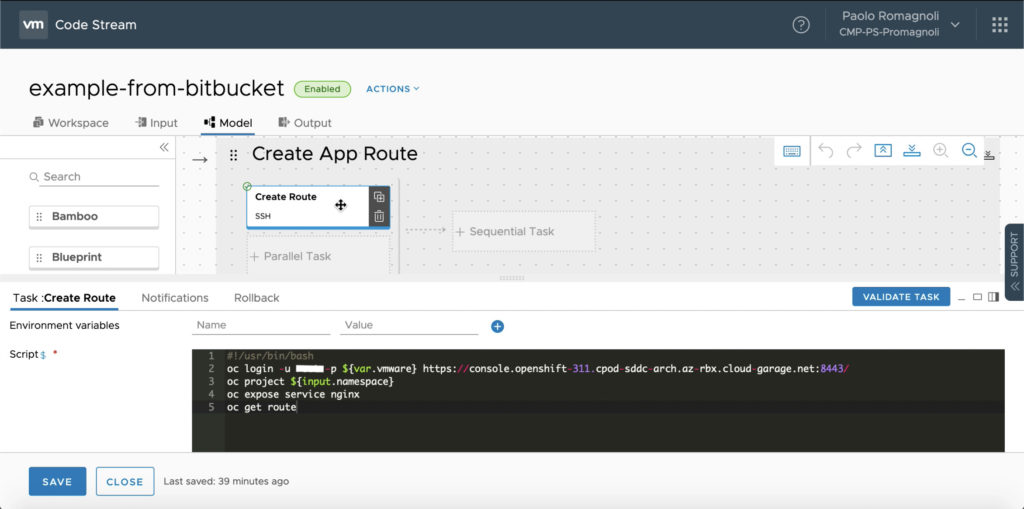
The final stage, Create App Route, peform a single task that is very specific to OpenShift.
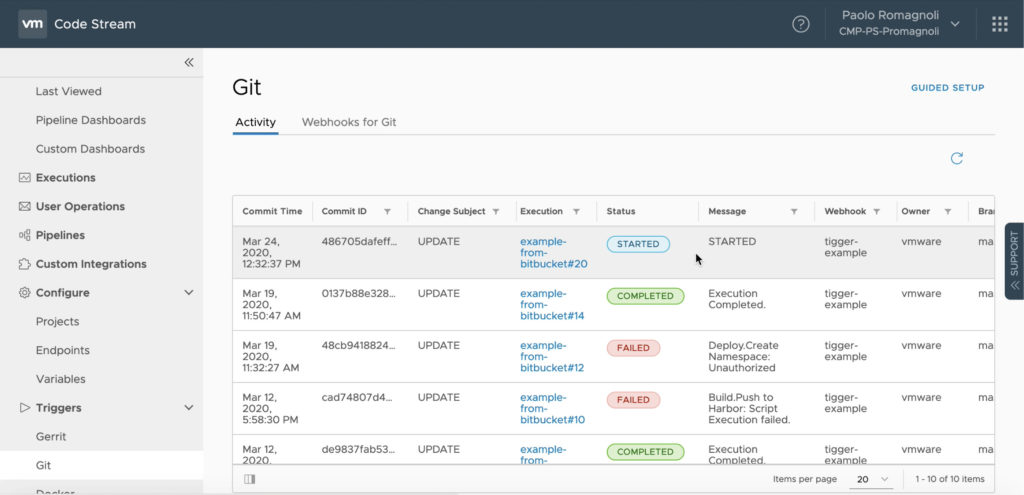
Let’s see it in action!
When developer push code on the Bitbucket repo the trigger start the pipeline.
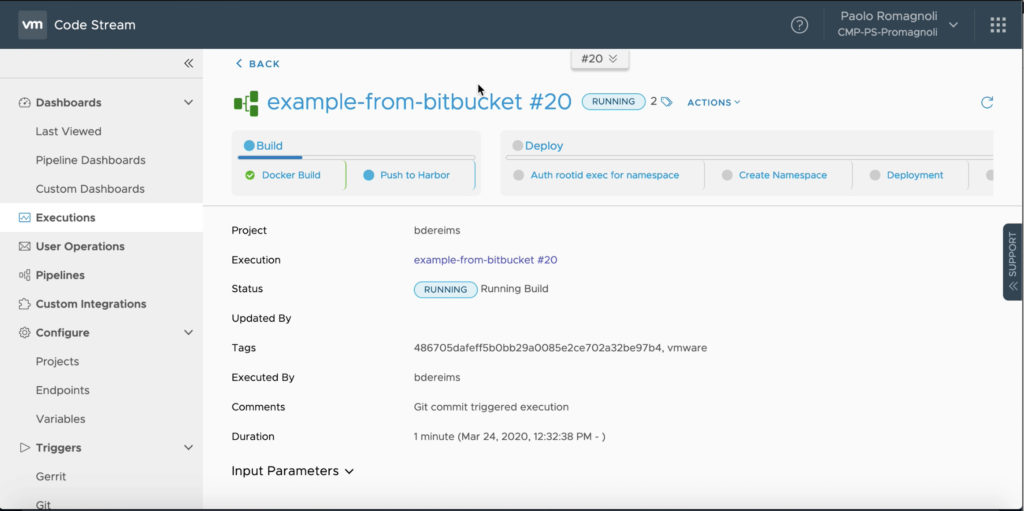
The user can live track the pipeline execution accessing logs, verifying variables binding and tasks output.
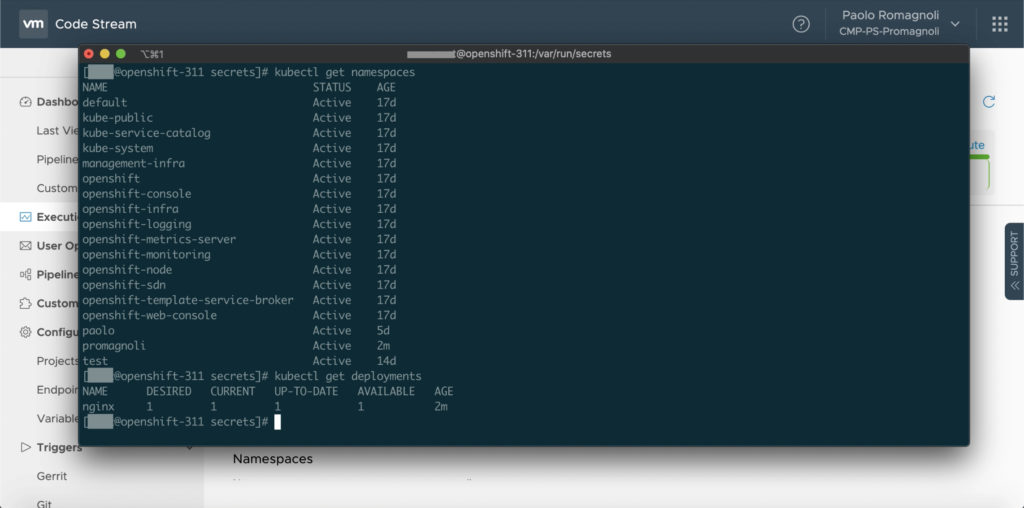
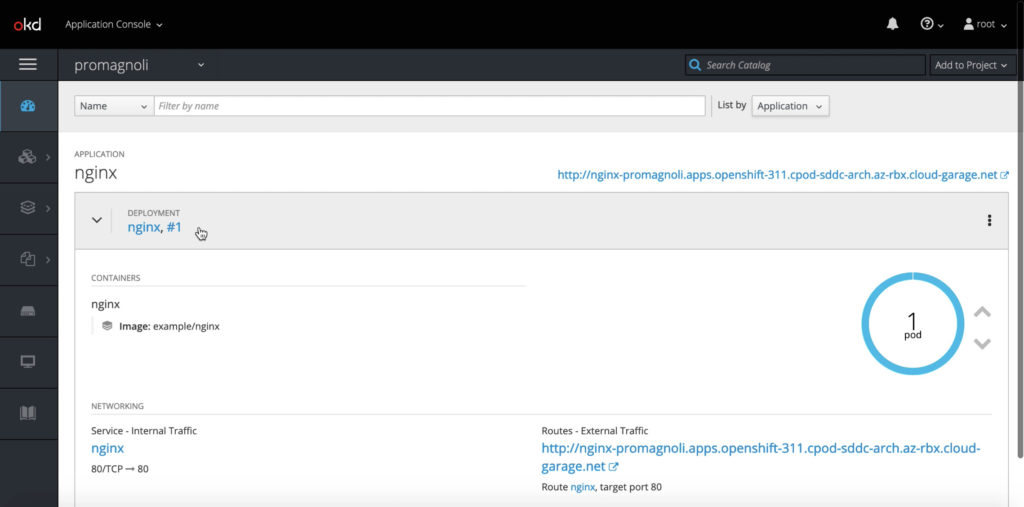
Of course user can check also through CLI and OpenShift UI.